728x90
이번 편에서 다루는 것
지금까지 구축한 기능들:
- 데이터 파이프라인
- XLM-R 임베딩
- 추천 알고리즘
- LLM 설명 보강
- 성능 최적화
이제 이것들을 실제 서비스로 배포할 차례다.
이번 편에서는 FastAPI 서버 구축, 인증 처리, 바이너리 빌드, 운영 서버 배포를 다룬다.
FastAPI 선택 이유
고려한 옵션 선택 여부 이유
| Django REST | ❌ | 이 프로젝트에는 과한 기능 |
| Flask | ❌ | 비동기 지원 부족 |
| FastAPI | ✅ | 비동기, 타입 힌트, 자동 문서화 |
선택 이유:
- AI 추론이 느릴 수 있어 비동기 처리 필요
- Pydantic 기반 타입 검증이 ML 파이프라인과 잘 맞음
- 자동 생성되는 API 문서 (Swagger UI)
API 설계
엔드포인트 설계
메서드 경로 설명
| GET | /api/v1/recommend/{student_id} | 학생별 추천 조회 |
| POST | /api/v1/recommend/generate/{student_id} | 특정 학생 추천 생성 |
| POST | /api/v1/recommend/generate-all | 전체 학생 추천 생성 |
| GET | /health | 헬스 체크 |
응답 스키마
from pydantic import BaseModel
from typing import List, Optional
class RecommendationItem(BaseModel):
""" 추천 항목 """
item_id: str
item_name: str
item_type: str # 'course' or 'activity'
rank: int
score: float
class RecommendationResponse(BaseModel):
""" 추천 응답 """
student_id: str
courses: List[RecommendationItem]
activities: List[RecommendationItem]
generated_at: str
class GenerateResponse(BaseModel):
""" 생성 응답 """
success: bool
message: str
count: Optional[int] = NoneAPI 서버 구현
메인 애플리케이션
from fastapi import FastAPI, HTTPException, Depends
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI(
title="AI 교과 추천 API",
description="학생 개인화 강좌 추천 서비스",
version="1.0.0"
)
# CORS 설정 (프론트엔드 연동 위해)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 운영에서는 특정 도메인만 허용
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
@app.get("/health")
async def health_check():
""" 헬스 체크 """
return {"status": "healthy"}추천 조회 API
from fastapi import APIRouter
from sqlalchemy.orm import Session
router = APIRouter(prefix="/api/v1/recommend", tags=["recommend"])
@router.get("/{student_id}", response_model=RecommendationResponse)
async def get_recommendations(
student_id: str,
db: Session = Depends(get_db)
):
""" 학생별 추천 조회 """
# DB에서 추천 결과 조회
recommendations = db.query(RecommendationTable).filter(
RecommendationTable.student_id == student_id
).all()
if not recommendations:
raise HTTPException(
status_code=404,
detail=f"학생 {student_id}의 추천 결과가 없습니다"
)
# 강좌와 활동 분리
courses = [r for r in recommendations if r.item_type == 'course']
activities = [r for r in recommendations if r.item_type == 'activity']
return RecommendationResponse(
student_id=student_id,
courses=[_to_item(c) for c in courses],
activities=[_to_item(a) for a in activities],
generated_at=recommendations[0].created_at.isoformat()
)
def _to_item(rec) -> RecommendationItem:
return RecommendationItem(
item_id=rec.item_id,
item_name=rec.item_name,
item_type=rec.item_type,
rank=rec.rank,
score=rec.score
)추천 생성 API
from fastapi import BackgroundTasks
@router.post("/generate/{student_id}", response_model=GenerateResponse)
async def generate_for_student(
student_id: str,
db: Session = Depends(get_db),
api_key: str = Depends(verify_api_key)
):
""" 특정 학생 추천 생성 """
recommender = get_recommender()
try:
result = recommender.recommend_for_student(student_id)
save_recommendations(db, student_id, result)
return GenerateResponse(
success=True,
message=f"학생 {student_id} 추천 생성 완료",
count=len(result)
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@router.post("/generate-all", response_model=GenerateResponse)
async def generate_all(
background_tasks: BackgroundTasks,
api_key: str = Depends(verify_api_key)
):
""" 전체 학생 추천 생성 (백그라운드) """
# 백그라운드에서 실행 (즉시 응답 반환)
background_tasks.add_task(run_batch_recommendation)
return GenerateResponse(
success=True,
message="전체 학생 추천 생성이 시작되었습니다"
)
async def run_batch_recommendation():
""" 배치 추천 생성 """
recommender = get_recommender()
students = get_all_students()
for student in students:
result = recommender.recommend_for_student(student['id'])
save_recommendations(student['id'], result)
API 키 인증
인증 미들웨어
from fastapi import Security, HTTPException, status
from fastapi.security import APIKeyHeader
from sqlalchemy.orm import Session
api_key_header = APIKeyHeader(name="X-API-Key", auto_error=False)
async def verify_api_key(
api_key: str = Security(api_key_header),
db: Session = Depends(get_db)
) -> str:
""" API 키 검증 """
if not api_key:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="API 키가 필요합니다"
)
# DB에서 API 키 확인
client = db.query(APIClient).filter(
APIClient.api_key == api_key,
APIClient.is_active == True
).first()
if not client:
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="유효하지 않은 API 키입니다"
)
return client.name
API 키 생성 유틸리티
import secrets
import hashlib
def generate_api_key() -> str:
""" 새 API 키 생성 """
return secrets.token_urlsafe(32)
def hash_api_key(api_key: str) -> str:
""" API 키 해시 (저장용) """
return hashlib.sha256(api_key.encode()).hexdigest()
통합 CLI 구현
모든 기능을 하나의 CLI로 통합했다.
import typer
import uvicorn
app = typer.Typer(
name="eduflow",
help="AI 교과 추천 시스템"
)
@app.command()
def serve(
host: str = typer.Option("0.0.0.0", "--host", "-h"),
port: int = typer.Option(8000, "--port", "-p"),
workers: int = typer.Option(1, "--workers", "-w"),
reload: bool = typer.Option(False, "--reload", "-r")
):
""" API 서버 실행 """
uvicorn.run(
"api.main:app",
host=host,
port=port,
workers=workers,
reload=reload
)
@app.command()
def migrate(
api: List[str] = typer.Option(None, "--api", "-a"),
incremental: bool = typer.Option(False, "--incremental", "-i"),
date: str = typer.Option(None, "--date", "-d")
):
""" 데이터 마이그레이션 """
# ... 구현
@app.command()
def recommend(
student: List[str] = typer.Option(None, "--student", "-s"),
all_students: bool = typer.Option(False, "--all", "-a")
):
""" 추천 생성 """
# ... 구현
@app.command()
def enhance(
year: int = typer.Option(None, "--year", "-y")
):
""" 강좌 설명 보강 """
# ... 구현
@app.command()
def version():
""" 버전 정보 """
print("EduFlow v1.0.0")
if __name__ == "__main__":
app()사용 예시
# 서버 실행
python main.py serve -p 8000
# 마이그레이션
python main.py migrate --api students courses
# 추천 생성
python main.py recommend --all
# 설명 보강
python main.py enhance --year 2024
바이너리 빌드 (Nuitka)
운영 서버에 Python 환경을 설치하지 않고, 단일 실행 파일로 배포하고 싶었다.
Nuitka 선택 이유
도구 방식 결과물
| PyInstaller | 번들링 | 디렉토리 |
| cx_Freeze | 번들링 | 디렉토리 |
| Nuitka | 컴파일 | 단일 바이너리 |
빌드 스크립트
#!/bin/bash
# build.sh
MODE=${1:-light} # light or full
if [ "$MODE" = "light" ]; then
# ML 모듈 제외 (서버, 마이그레이션만)
python -m nuitka \\
--standalone \\
--onefile \\
--output-filename=eduflow-light.bin \\
--include-package=fastapi \\
--include-package=uvicorn \\
--include-package=sqlalchemy \\
--include-package=psycopg2 \\
--nofollow-import-to=torch \\
--nofollow-import-to=transformers \\
--nofollow-import-to=sentence_transformers \\
main.py
else
# 전체 빌드 (ML 포함)
python -m nuitka \\
--standalone \\
--onefile \\
--output-filename=eduflow.bin \\
--include-package=fastapi \\
--include-package=uvicorn \\
--include-package=sqlalchemy \\
--include-package=torch \\
--include-package=transformers \\
main.py
fi
echo "빌드 완료: dist/eduflow-${MODE}.bin"Docker 크로스 빌드
운영 서버(Rocky Linux)와 맞는 바이너리를 빌드하기 위해 Docker를 사용했다.
# Dockerfile.build
FROM rockylinux:9
# 의존성 설치
RUN dnf install -y python3.11 python3.11-pip gcc gcc-c++ patchelf
WORKDIR /app
# 패키지 설치
COPY requirements.txt .
RUN pip3.11 install -r requirements.txt
RUN pip3.11 install nuitka
# 소스 복사
COPY . .
# 빌드
RUN chmod +x build.sh && ./build.sh light
# 결과물 복사를 위한 단계
FROM scratch
COPY --from=0 /app/dist/eduflow-light.bin /eduflow-light.bin# 빌드 실행
docker build -f Dockerfile.build -t eduflow-build .
docker cp $(docker create eduflow-build):/eduflow-light.bin ./dist/운영 서버 배포
배포 구조
/app/
├── eduflow-light.bin # 실행 파일
├── .env # 환경 변수
├── config.json # 설정 파일
└── models/ # AI 모델 (추천 생성 시 필요)
├── xlm-r/
└── llm/환경 변수 설정
# .env
DB_ENV=production
DB_PASSWORD=***
API_ACCESS_KEY=***
AUTH_SECRET_KEY=***
systemd 서비스 등록
# /etc/systemd/system/eduflow.service
[Unit]
Description=EduFlow AI Recommendation API
After=network.target
[Service]
Type=simple
User=app
WorkingDirectory=/app
ExecStart=/app/eduflow-light.bin serve -p 8000
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target# 서비스 시작
sudo systemctl daemon-reload
sudo systemctl enable eduflow
sudo systemctl start eduflow
Cron 배치 설정
# crontab -e
# 매일 새벽 2시: 데이터 동기화
0 2 * * * cd /app && ./eduflow-light.bin migrate --incremental --date $(date -d yesterday +\\%Y\\%m\\%d)
# 매일 새벽 3시: 추천 생성
0 3 * * * cd /app && ./eduflow-light.bin recommend --all모니터링
헬스 체크
# 서버 상태 확인
curl <http://localhost:8000/health>
# {"status": "healthy"}
로그 확인
# 서비스 로그
journalctl -u eduflow -f
# 최근 100줄
journalctl -u eduflow -n 100
최종 시스템 구성도
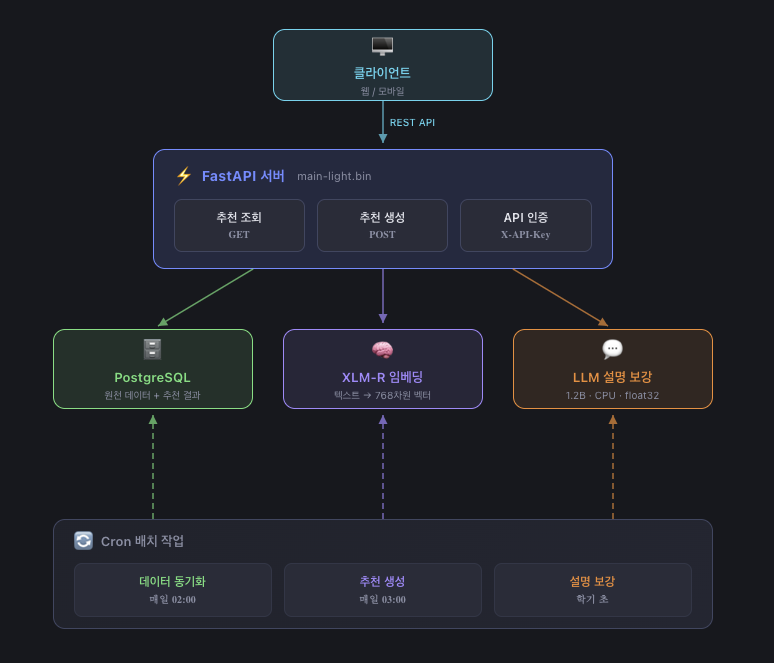
프로젝트 회고
성과 요약
| 항목 | 수치 |
| 대상 학생 | 5,000명+ |
| 추천 강좌 | 2,000개+ |
| 추천 활동 | 500개+ |
| 전체 파이프라인 | 약 28분 |
| LLM 성능 개선 | 27배 |
기술 스택
- Backend: Python, FastAPI, SQLAlchemy
- Database: PostgreSQL
- AI/ML: PyTorch, XLM-R, LLM (1.2B)
- Infra: Nuitka, Docker, systemd
배운 점
- 데이터 품질이 AI의 기반: 알고리즘보다 데이터가 중요
- 환경을 고려한 설계: GPU 없이도 동작하는 시스템
- 성능 측정 필수: 최적화는 측정에서 시작
- 단순함이 최고: 복잡한 해결책보다 단순한 해결책
- End-to-End 경험: 설계부터 배포까지 전 과정 경험
시리즈를 마치며
7편에 걸쳐 AI 교과 추천 시스템 개발 과정을 공유했습니다.
이 프로젝트를 통해 다음을 경험했습니다:
- 외부 API 연동 및 데이터 파이프라인 구축
- XLM-R을 활용한 텍스트 임베딩
- 가중치 기반 하이브리드 추천 알고리즘
- LLM을 활용한 데이터 품질 개선
- CPU 환경에서의 성능 최적화
- 바이너리 빌드 및 운영 배포
읽어주셔서 감사합니다.
시리즈 목차 (전체)
- 프로젝트 소개 - 왜 AI 추천이 필요했나
- 추천을 위한 데이터 파이프라인 설계
- XLM-R로 강좌 임베딩 구축하기
- 추천 알고리즘 설계 - 가중치 기반 개인화
- LLM으로 강좌 설명 보강하기
- 성능 최적화 - CPU에서 27배 빠르게
- API 서버 구축과 배포 ← 현재 글 (완결)
728x90
'프로그래밍 > AI 교과 추천 시스템 개발기' 카테고리의 다른 글
| 6편. 성능 최적화 - CPU에서 27배 빠르게 (0) | 2026.02.20 |
|---|---|
| 5편. LLM으로 강좌 설명 보강하기 (0) | 2026.02.19 |
| 4편. 추천 알고리즘 설계 - 가중치 기반 개인화 (0) | 2026.02.18 |
| 3편. XLM-R로 강좌 임베딩 구축하기 (0) | 2026.02.17 |
| 2편. 추천을 위한 데이터 파이프라인 설계 (0) | 2026.02.16 |